Form Datasets¶
Workflows sometimes require access to historical data, standard data tables, lists of people, or other information. You can include that data directly in the form, attach it as a CSV file, or define it in an Entity List which can be shared between forms. All of these sources of data can be used to build select questions or to look up specific values.
Internal datasets are defined in the choices sheet of an XLSForm and are typically used as choices for selects. You can also define a dataset in the choices sheet to look up values based on user input. Learn how to define internal datasets in the section on selects.
External datasets can either be files that get attached to the form or Entity Lists. Entity Lists can be thought of as CSVs that are managed by ODK Central so that data collected by one form submission can be automatically accessible in other forms in the same project.
External datasets, whether they are attached files or Entity Lists, are useful when:
data comes from another system. Using external datasets generally requires fewer steps than adding the data to a form definition.
data needs to change over time. External datasets can be updated without modifying the form definition.
data is reused between forms. It may be easier to attach the same data file to multiple forms instead of copying the data into all the form definitions. Entity Lists are often even more convenient because they be shared between forms and automatically kept up-to-date.
the same forms are used in different contexts. For example, the exact same form definition could be used in multiple countries with different data files or Entity Lists representing districts, species, or products.
The more dynamic the data is, the more likely you are to benefit from Entity Lists over attached files.
Note
Most mobile devices released in 2019 or later can handle lists of 50,000 or more elements without slowing down. If you experience ODK Collect slowing down, please share the size of the dataset, the device you are using, and any expressions that reference the dataset on the community forum or to support@getodk.org.
Building selects from CSV files¶
CSV files can be used as choice lists for select questions using select_one_from_file or select_multiple_from_file. CSV files used this way must have name and label columns or you use the parameters column to customize the columns used. For each row in the dataset, the text in the value column (defaults to name) will be used as the value saved when that choice is selected and the text in the label column (defaults to label) will be used to display the choice.
Warning
For select multiples, name must not contain spaces.
Attached CSV files may also have any number of additional columns for use in choice filters or other expressions. The example below uses one select from internal choices followed by selects from two different external CSV files.
type |
name |
label |
choice_filter |
|---|---|---|---|
select_one states |
state |
State |
|
select_one_from_file lgas.csv |
local_gov_area |
Local Government Area |
state=${state} |
select_multiple_from_file wards.csv |
wards |
Wards |
lga=${local_gov_area} |
list_name |
name |
label |
population |
|---|---|---|---|
states |
abia |
Abia |
4112230 |
states |
ebonyi |
Ebonyi |
2176947 |
name |
label |
state |
|---|---|---|
aba_n |
Aba North |
abia |
aba_s |
Aba South |
abia |
afikpo_n |
Afikpo North |
ebonyi |
name |
label |
lga |
|---|---|---|
eziama |
Eziama |
aba_n |
umuogor |
Umuogor |
aba_n |
ezeke_amasiri |
Ezeke amasiri |
afikpo_n |
poperi_amasiri |
Poperi amasiri |
afikpo_n |
Building selects from Entity Lists¶
Entity Lists can be used as choice lists for select questions using select_one_from_file or select_multiple_from_file. All Entities have a name and label which are used by default as the value and label for choices.
If you would like to use other properties as values or labels, you can specify those in the parameters column of your XLSForm. Additional properties can be used in choice filters or other expressions, just like the columns in a CSV.
Building selects from GeoJSON files¶
New in ODK Collect v2022.2.0, ODK Central v1.4.0; Polygons and lines in Collect v2023.1.0; Web Forms support in Central v2025.3
GeoJSON files that follow the GeoJSON spec can be used to populate select question choices using select_one_from_file. Selects from GeoJSON may be styled as maps using the map appearance but can also use any other select appearance. In order to be used by a form, a GeoJSON file:
must have a
.geojsonextension (NOT.json)must define a single top-level FeatureCollection
must include a unique identifier for each feature (by default, a top-level
id, falling back to anidproperty, or can be configured)must only include features with Point, LineString or Polygon types
type |
name |
label |
|---|---|---|
select_one_from_file museums.geojson |
museum |
Select the museum closest to you |
GeoJSON files referenced in forms can have any number of features and any number of custom properties.
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [
7.0801379,
46.5841618
]
},
"properties": {
"id": "fs87b",
"title": "HR Giger Museum",
"annual_visits": 40000
}
}
]
}
All properties are displayed by select from map questions and can be referenced by any part of the form, just like the columns in a CSV.
Given the GeoJSON file and the form definition above, if the user selected "HR Giger Museum", the value of ${museum} would be "fs87b".
A feature's geospatial representation can be accessed as geometry and is provided in the ODK format. For example, the expression instance('museums')/root/item[id=${museum}]/geometry evaluates to 46.5841618 7.0801379 0 0 which is a point in the ODK format.
Building selects from XML files¶
XML files can be used as choice lists for select questions using select_one_from_file or select_multiple_from_file. This is typically less convenient than using CSV files. However, knowing about the XML representation is helpful for understanding how to look up values in both CSV and XML files.
XML files used for selects must have the following structure and can have any number of item blocks:
<root> <item> <name>...</name> <label>...</label> ... </item> ... </root>
The item blocks are analogous to rows in the CSV representation. Each item must have at least name and label nested nodes and can have any number of additional nodes. These nodes correspond to columns in the CSV representation.
Looking up values in datasets¶
You can look up values from internal or external datasets. You can look up values and save them for analysis or use in other expressions by using a calculate. You can also use lookup expressions directly in constraints and other expressions or use them directly in labels to display them to users.
In the example below, a user is first prompted to select a participant from the list of people found in an external file. Then, the selected participant's name is used to look up the place that participant is assigned to. A second dataset is attached from a places.csv file using csv-external. The assigned place is looked up by name and its label is displayed directly in a note.
type |
name |
label |
calculation |
|---|---|---|---|
select_one_from_file people |
participant |
Participant |
|
calculate |
assigned_place |
instance("people")/root/item[name=${participant}]/place |
|
csv-external |
places |
||
note |
place_note |
Assigned place: instance("places")/root/item[name=${assigned_place}]/label |
name |
label |
population |
enumerator |
|---|---|---|---|
c2139aae-5… |
Ifedore |
270900 |
6234 |
f1ad1a8a-c… |
Magama |
311300 |
2742 |
name |
label |
place |
visits |
last_visit |
phone |
|---|---|---|---|---|---|
da0ee575-d… |
Xue (Ifedore) - 2341745 |
c2139aae-5… |
1 |
2024-5-1 |
2341745 |
c51c32ac-1… |
Dia (Ifedore) - 9868545 |
c2139aae-5… |
3 |
2024-4-12 |
9868545 |
Lookup expressions¶

Expressions to look up values in datasets always start with instance("<instance name>") to identify which dataset is being accessed. If you have a choice list named people or an attached CSV with filename people.csv, your lookup expressions will start with instance("people").
The next part of the expression is /root/item. Each row in your choice list or attached file represents an item. /root/item selects all of those items.
Note
You don't need to deeply understand the detail of these expressions to use them effectively. If you're interested in learning more, see the section on XPath paths. In particular, /root/item comes from the XML structure used to represent datasets for selects. If you attach custom XML files to your form, this part of the expression may be different.
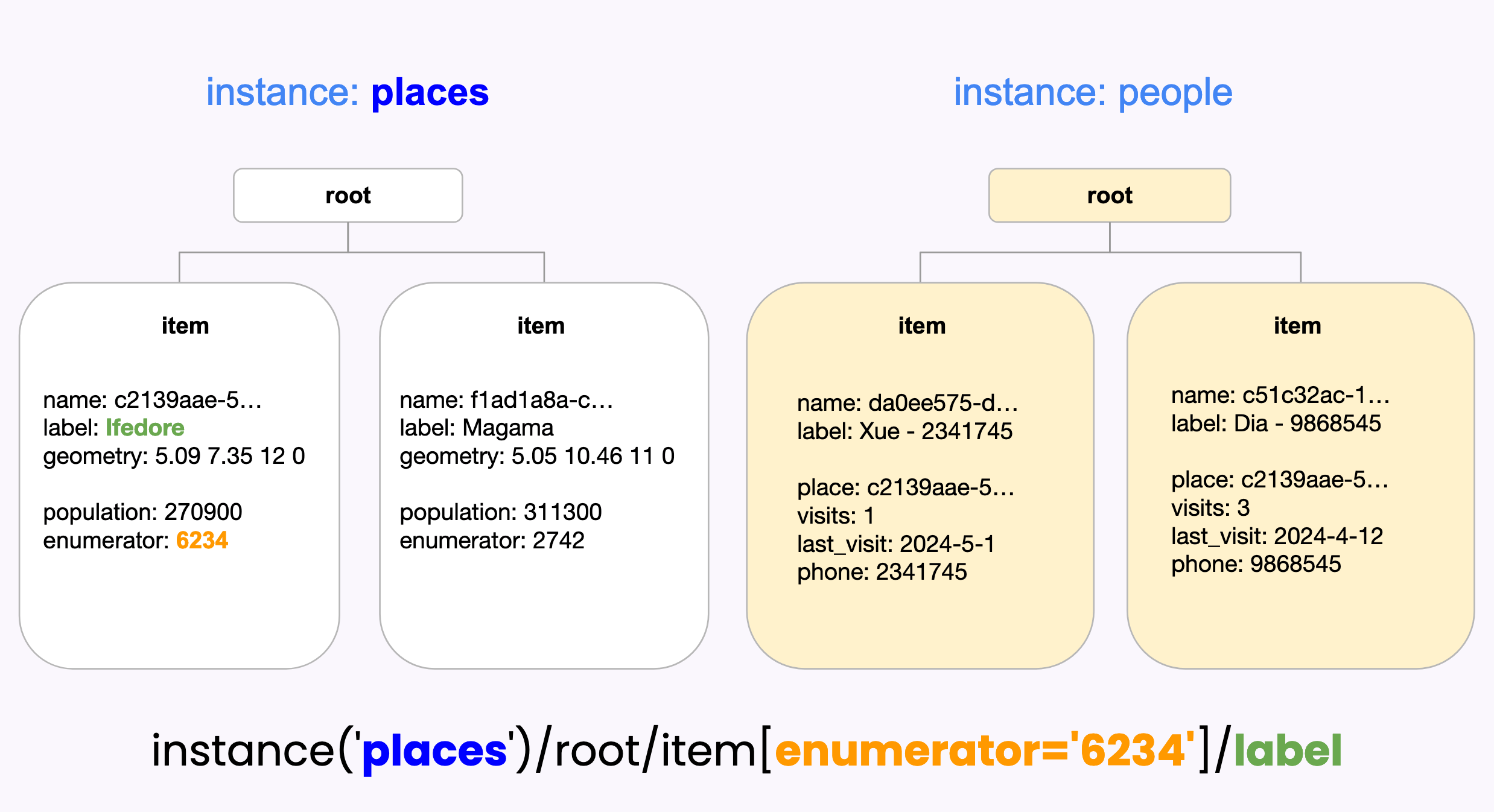
You then generally need an expression in square brackets to filter down the list of items to only the ones you care about. For example, if you have a choice list or attached file named people and want to look up a value about a person that was selected in a form field called participant, you would use name = ${participant} as your filter expression. name is the default property used to uniquely identify items in choices lists or Entity Lists. You can also filter the list by any other property. For example, see the image below for an example that filters a place list based on an enumerator property.
Note
Most filter expressions you will write will use comparisons with = as in name = ${participant}. Typically, the left side of the = will be a property or column from your list, written without ${}, and the right side will be a field from your form, written with ${}. If you have more complex filtering needs, you can use any expression that evaluates to True or False. These filter expressions are exactly the same kind of expression used to define a choice filter.
Once you have filtered down the list to the item or items that you care about, you generally will specify which property of the item(s) you want to look up. For example, if your dataset has a phone property and you want to look the phone number for the selected participant, your full expression would look like instance("people")/root/item[name = ${participant}]/phone.
Warning
If your filter expression matches multiple items and you try to look up a single value, you will get a type mismatch crash in ODK Collect. Learn how to fix this.
See the image below for a visual representation of the form example presented at the start of this section. You can see that there are two separate datasets with names places and people. Each dataset has a root and multiple items connected to that root.
Below the representation of the two datasets, there is the expression instance("places")/root/item[enumerator='6234']/label. When that expression is evaluated, first the places dataset is selected. Then, for each item in the dataset, the enumerator property is compared against the value '6234'. There is exactly one match: the item with name starting with c2139. The label for that item is Ifedore so that is the result of evaluating the whole expression.
Calculating counts, sums, and other aggregates from dataset values¶
Your filter expression can result in one or more items being selected. Filtering to a result that includes multiple items is particularly useful for sums and counts. For example, to count the number of states with a population above a certain threshold:
count(instance("states")/root/item[population > ${pop_threshold}])
To get the total population across states with a population above a certain threshold:
sum(instance("states")/root/item[population > ${pop_threshold}]/population)
Attaching CSVs for lookups without a select¶
If you want to look up a value in a CSV directly without first going through a selection step, you can attach that CSV with csv-external:
type |
name |
label |
calculation |
|---|---|---|---|
csv-external |
people |
||
barcode |
person_id |
Scan person's ID card |
|
calculate |
person_fname |
instance("people")/root/item[code=${person_id}]/fname |
The example form above attaches a CSV with filename people.csv or an entity list named people. It then prompts the user to scan a barcode from an ID card and uses the value from the ID card to look up the corresponding person's first name. If attaching an actual CSV file, it must have columns named fname and code. Similarly, if using an entity list, that entity list must have properties named fname and code.
Note
To attach an XML file named people.xml instead, replace csv-external above with xml-external.